This package creates SHAP (SHapley Additive exPlanation) visualization plots for ‘XGBoost’ in R. It provides summary plot, dependence plot, interaction plot, and force plot. It relies on the SHAP implementation provided by ‘XGBoost’ and ‘LightGBM’. Please refer to ‘shap/shap’ for the original implementation of SHAP in Python. Please note that the SHAP values are generated by ‘XGBoost’ and ‘LightGBM’; we just plot them. So the package cannot be used directly for other tree models like the random forest. Please refer to the “Note on the package” for more details.
All the functions except the force plot return ggplot object thus it is possible to add more layers. The dependence plot shap.plot.dependence returns ggplot object if without the marginal histogram by default.
To revise feature names, you could define a global variable named new_labels, the plotting functions will use this list as new feature labels. The SHAPforxgboost::new_labels is a placeholder default to NULL. Or you could overwrite the labels by adding a labs layer to the ggplot object.
Please refer to this blog as the vignette: more examples and discussion on SHAP values in R, why use SHAP, and a comparison to Gain: SHAP visualization for XGBoost in R
Installation
Please install from CRAN or Github:
install.packages("SHAPforxgboost")
devtools::install_github("liuyanguu/SHAPforxgboost")Example
Summary plot
# run the model with built-in data, these codes can run directly if package installed
library("SHAPforxgboost")
y_var <- "diffcwv"
dataX <- as.matrix(dataXY_df[,-..y_var])
# hyperparameter tuning results
params <- list(objective = "reg:squarederror", # For regression
eta = 0.02,
max_depth = 10,
gamma = 0.01,
subsample = 0.98,
colsample_bytree = 0.86)
dtrain <- xgboost::xgb.DMatrix(
data = dataX,
label = dataXY_df[[y_var]]
)
watch <- list(train = dtrain)
mod <- xgboost::xgb.train(
params = params,
data = dtrain,
nrounds = 200,
evals = list(train = dtrain),
early_stopping_rounds = 8,
verbose = 0
)
# To return the SHAP values and ranked features by mean|SHAP|
shap_values <- shap.values(xgb_model = mod, X_train = dataX)
# The ranked features by mean |SHAP|
shap_values$mean_shap_score
# To prepare the long-format data:
shap_long <- shap.prep(xgb_model = mod, X_train = dataX)
# is the same as: using given shap_contrib
shap_long <- shap.prep(shap_contrib = shap_values$shap_score, X_train = dataX)
# (Notice that there will be a data.table warning from `melt.data.table` due to `dayint` coerced from
# integer to double)
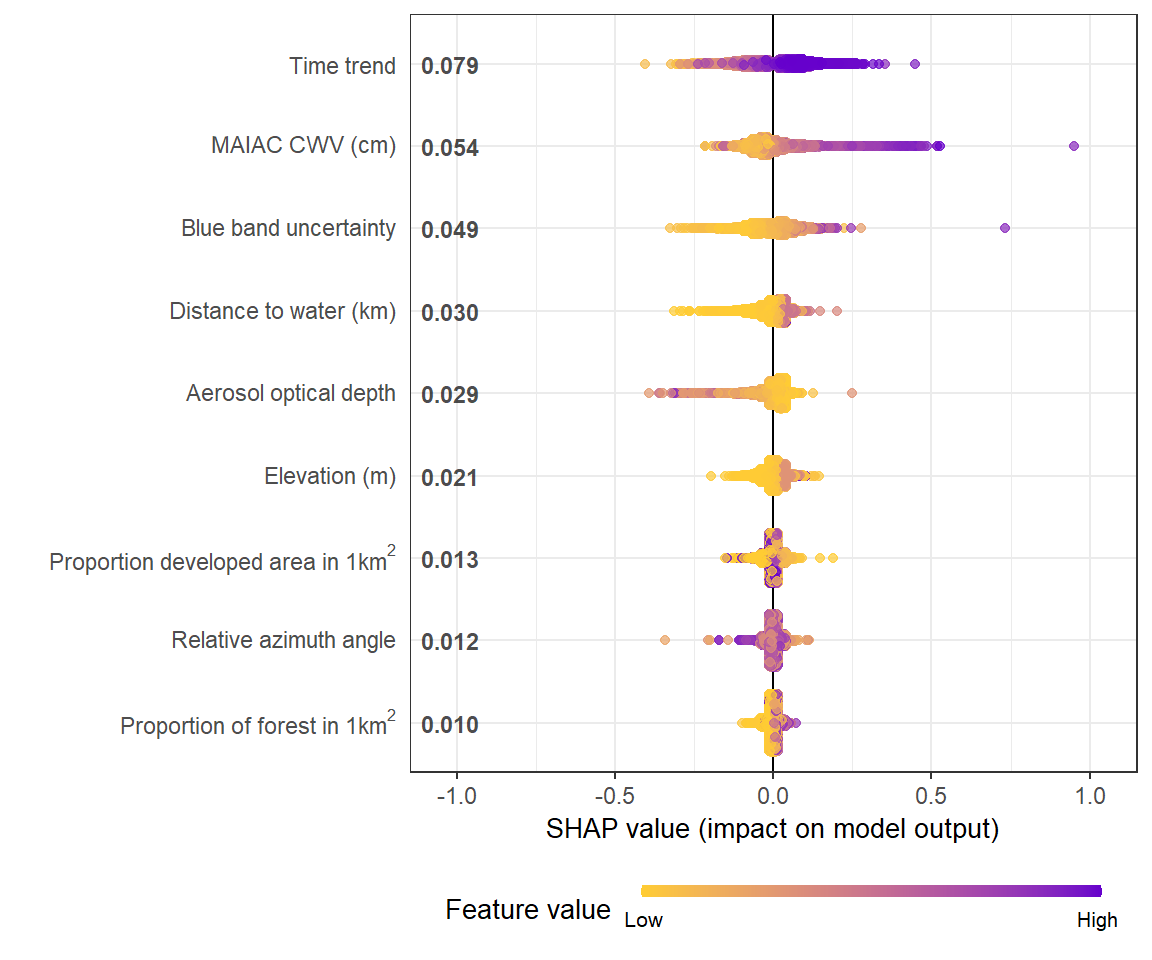
# **SHAP summary plot**
shap.plot.summary(shap_long)
# sometimes for a preview, you want to plot less data to make it faster using `dilute`
shap.plot.summary(shap_long, x_bound = 1.2, dilute = 10)
# Alternatives options to make the same plot:
# option 1: start with the xgboost model
shap.plot.summary.wrap1(mod, X = dataX)
# option 2: supply a self-made SHAP values dataset (e.g. sometimes as output from cross-validation)
shap.plot.summary.wrap2(shap_values$shap_score, dataX)
Dependence plot
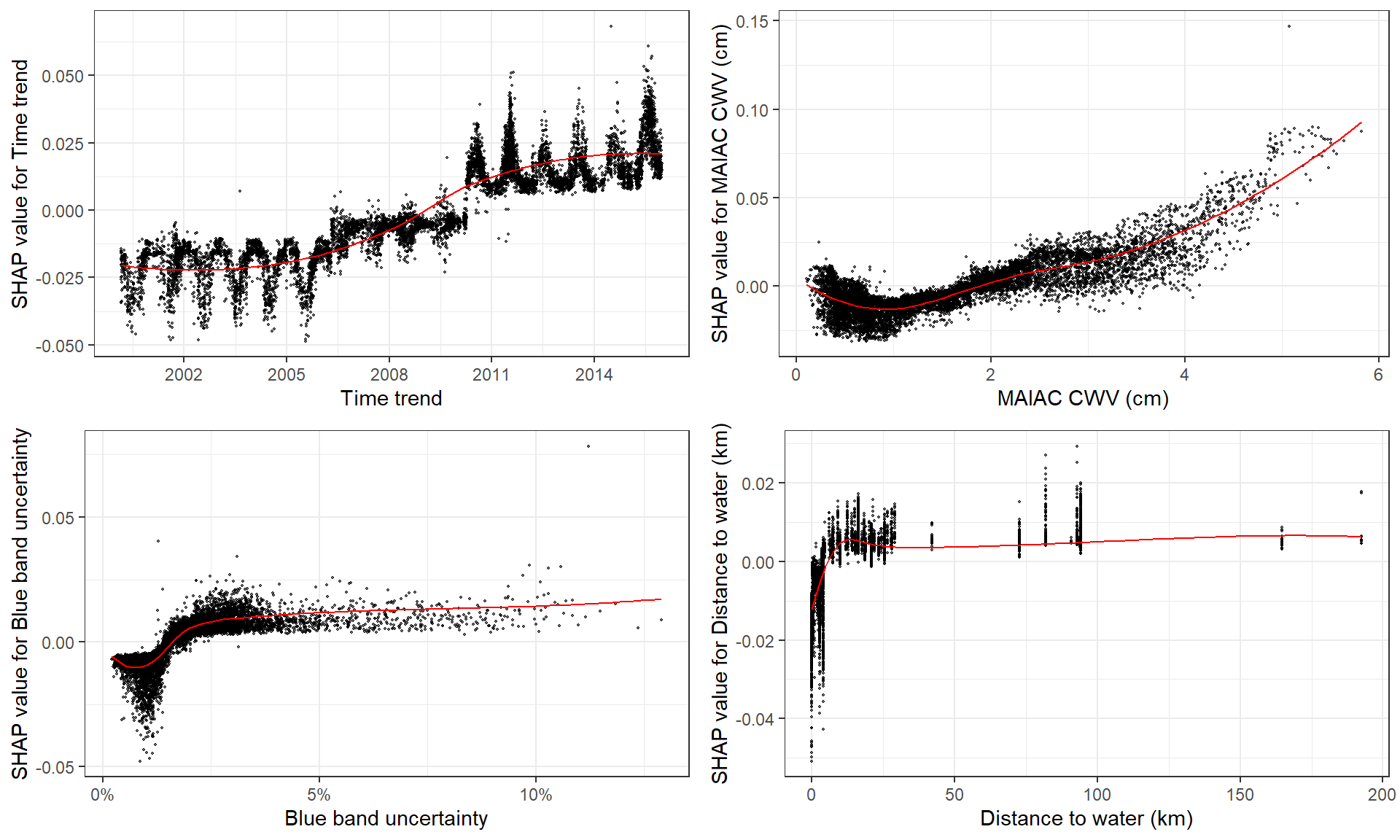
# **SHAP dependence plot**
# if without y, will just plot SHAP values of x vs. x
shap.plot.dependence(data_long = shap_long, x = "dayint")
# optional to color the plot by assigning `color_feature` (Fig.A)
shap.plot.dependence(data_long = shap_long, x= "dayint",
color_feature = "Column_WV")
# optional to put a different SHAP values on the y axis to view some interaction (Fig.B)
shap.plot.dependence(data_long = shap_long, x= "dayint",
y = "Column_WV", color_feature = "Column_WV")
# To make plots for a group of features:
fig_list = lapply(names(shap_values$mean_shap_score)[1:6], shap.plot.dependence,
data_long = shap_long, dilute = 5)
gridExtra::grid.arrange(grobs = fig_list, ncol = 2)SHAP interaction plot
This example will take very long, don’t run it, try a small dataset or check the example in shap.prep.interaction.
# prepare the data using either:
# notice: this step is slow since it calculates all the combinations of features.
# It may take very long on personal laptop.
shap_int <- shap.prep.interaction(xgb_mod = mod, X_train = dataX)
# it is the same as:
shap_int <- predict(mod, dataX, predinteraction = TRUE)
# **SHAP interaction effect plot **
shap.plot.dependence(data_long = shap_long,
data_int = shap_int,
x= "Column_WV",
y = "AOT_Uncertainty",
color_feature = "AOT_Uncertainty")
SHAP force plot
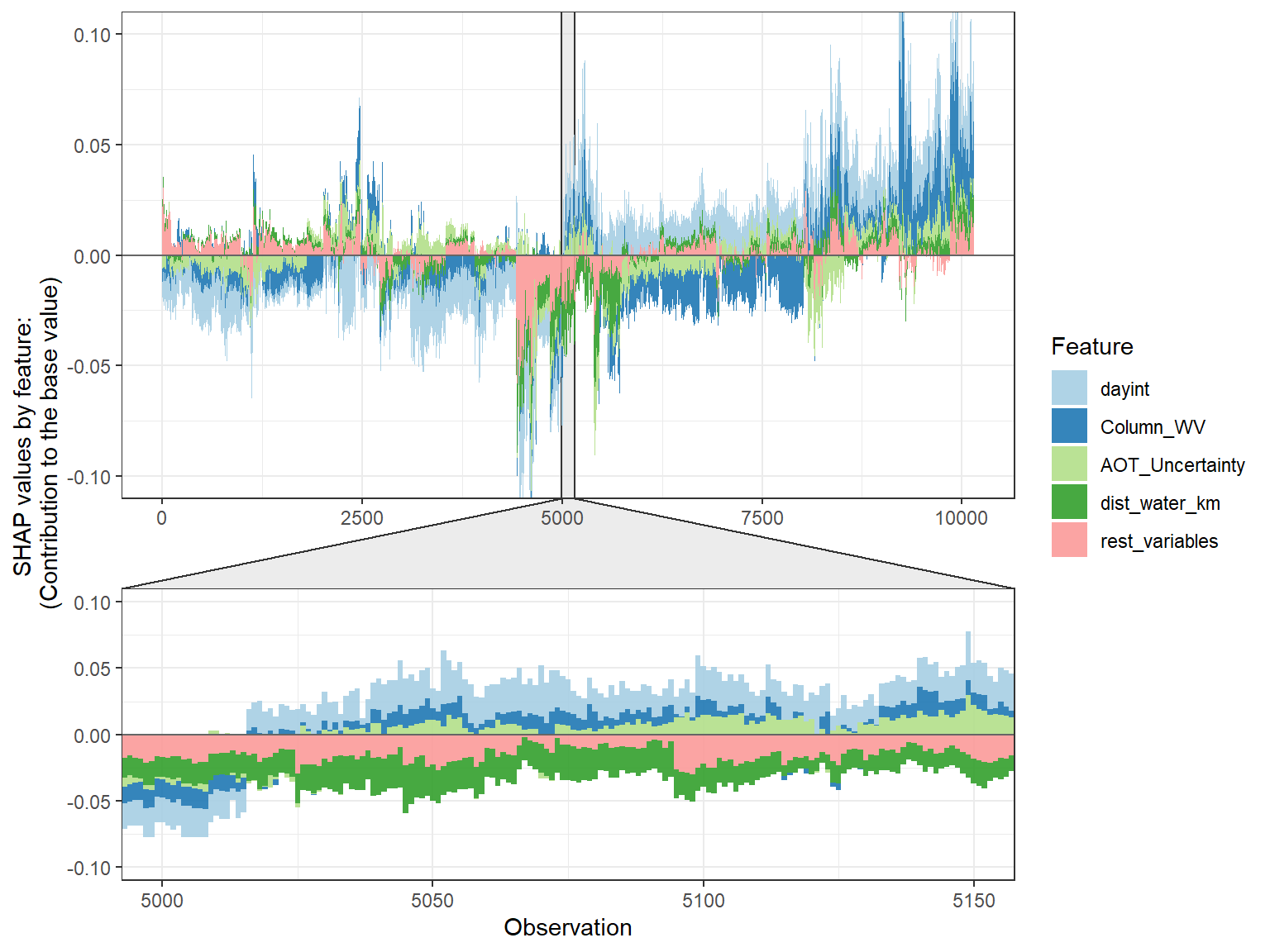
# choose to show top 4 features by setting `top_n = 4`, set 6 clustering groups.
plot_data <- shap.prep.stack.data(shap_contrib = shap_values$shap_score, top_n = 4, n_groups = 6)
# choose to zoom in at location 500, set y-axis limit using `y_parent_limit`
# it is also possible to set y-axis limit for zoom-in part alone using `y_zoomin_limit`
shap.plot.force_plot(plot_data, zoom_in_location = 500, y_parent_limit = c(-1,1))
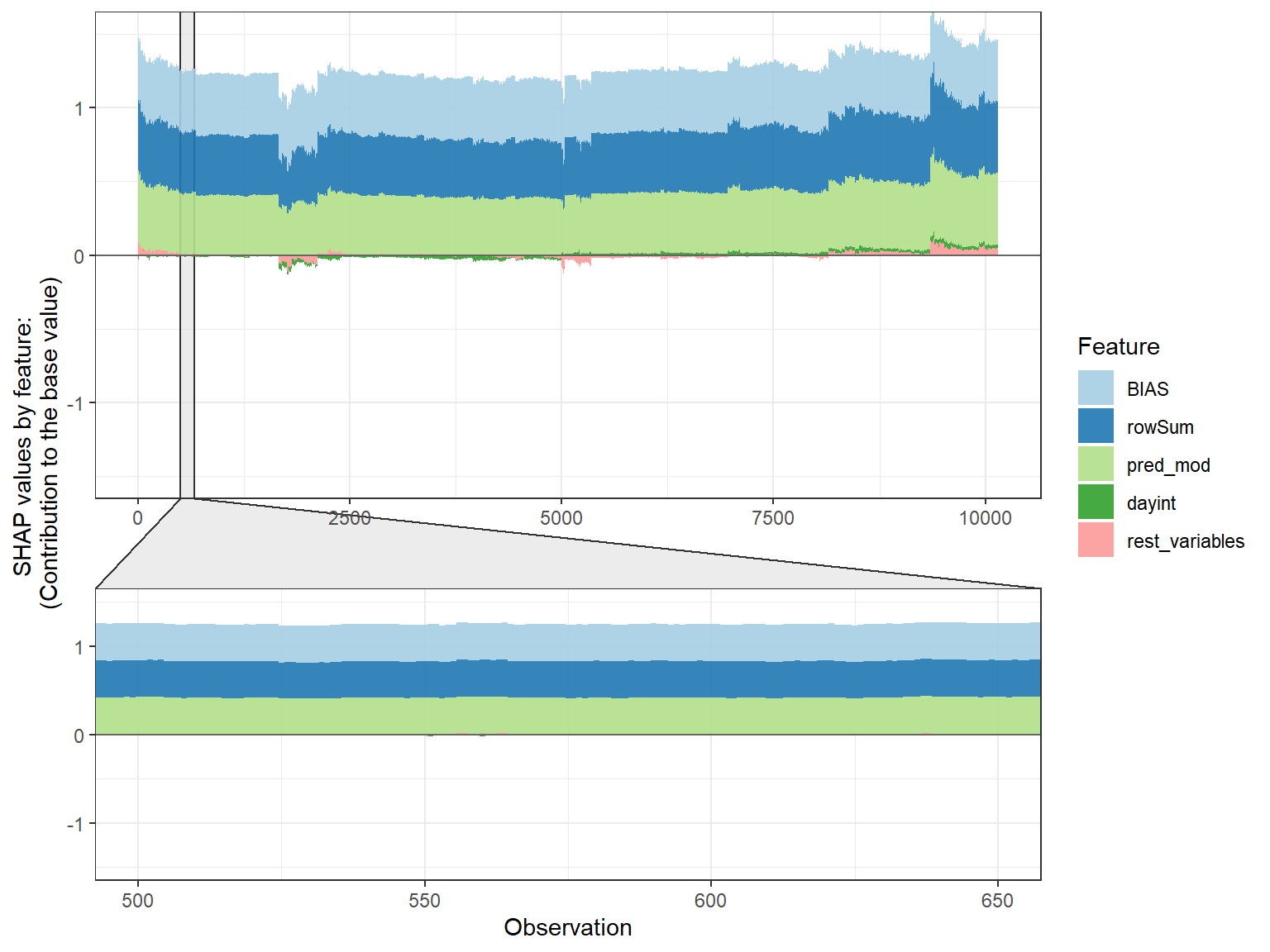
# plot by each cluster
shap.plot.force_plot_bygroup(plot_data)
Note on the package
SHAP values
SHAPforxgboost plots the SHAP values returned by the predict function. The shap.values function obtains SHAP values using:
predict(object = xgb_model, newdata = X_train, predcontrib = TRUE)If you are using ‘XGBoost’, see ?xgboost::predict.xgb.Booster for more details. If you are new to SHAP plot, it may be a good idea to try the examples in the default SHAP plotting function in the ‘XGBoost’ package first:
?xgboost::xgb.plot.shapCross-validation
Although the function shap.values names the parameter X_train, it is just the data you would provide to the predict function together with the xgboost model object to make predictions. So it can be training data or testing data. SHAP values help to explain how the model works and how each feature contributes to the predicted values.
As an example of feature selection using SHAP values: if uses 5-fold cross-validation, for each round, the model is fit using 4/5 of the data, then the predictions are obtained using the 1/5 withheld data. Then SHAP values are obtained for these 1/5 testing data. After the 5 iterations, we combine the 5 groups of SHAP values (just like how we obtain the overall y_hat) for the 5 folds to get SHAP values in the same dimension as the data_X and can use SHAP values to rank feature importance. Hyper-parameter tuning of the model is performed separately in each round of cross-validation.
Citation
The citation could be seen obtained using citation("SHAPforxgboost")
To cite package ‘SHAPforxgboost’ in publications use:
Yang Liu and Allan Just (2020). SHAPforxgboost: SHAP Plots for 'XGBoost'. R package version 0.1.0.
https://github.com/liuyanguu/SHAPforxgboost/
A BibTeX entry for LaTeX users is
@Manual{,
title = {SHAPforxgboost: SHAP Plots for 'XGBoost'},
author = {Yang Liu and Allan Just},
year = {2020},
note = {R package version 0.1.0},
url = {https://github.com/liuyanguu/SHAPforxgboost/},
}Reference
Our lab’s paper applying this package:
Gradient Boosting Machine Learning to Improve Satellite-Derived Column Water Vapor Measurement Error
Corresponding SHAP plots package in Python: https://github.com/shap/shap
Paper 1. 2017 A Unified Approach to Interpreting Model Predictions
Paper 2. 2019 Consistent Individualized Feature Attribution for Tree Ensembles
Paper 3. 2019 Explainable AI for Trees: From Local Explanations to Global Understanding